
В Лаборатории искусственного интеллекта MIT опубликовали Speech2Face — модель, которая реконструирует лицо человека по записи его голоса. Нейросеть обучалась на миллионах видеозаписей с YouTube, на которых демонстрируется разговор человека.
Задача заключалась в том, чтобы понять, может ли голос отражать внешние характеристики его обладателя. Исследователи не фокусировались на том, чтобы точно реконструировать портрет человека по голосу, а на том, чтобы восстановить основные внешние характеристики.
Архитектура модели
На вход модель принимает спектограмму аудиозаписи голоса. Спектограмма — визуальное представление аудиоволн. На выходе модель отдает вектор размером в 4096 с характеристиками лица, который затем декодируется в изображение лица. Декодирование из вектора с характеристиками в изображение лица происходит с помощью предобученной нейросети.
Обучалась модель на датасете AVSpeech. Для этой цели исследователи использовали предобученную VGG-Face.
Пайплайн обучения модели можно разделить на два шага:
- Кодировщик голоса, который принимает на вход спектограмму и предсказывает вектор с характеристиками лица человека;
- Декодировщик лица, который принимает на вход вектор с характеристиками лица человека и генерирует лицо человека в стандартном формате (анфас и безэмоциональное)
Во время обучения декодировщик лица был зафиксирован и обучался только кодировщик голоса. Декодировщик лица исследователи взяли готовым из работы Cole et al.
Оценка работы модели
Нейросеть была протестирована с помощью качественных и количественных метрик. Во время экспериментов модель тестировалась на датасетах AVSpeech и VoxCeleb. Ниже можно, что чем длиннее входная аудиозапись (3 сек против 6 сек), тем выше количественная метрика и тем ближе сгенерированное изображение к истинному.
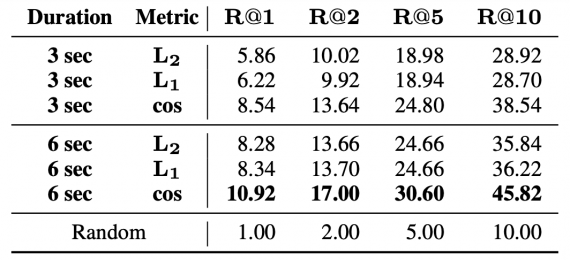
Recall в зависимости от длительности входных аудиозаписей (3 или 6 сек) и метрики

Сравнение сгенерированных изображений в зависимости от длительности входных аудиозаписей
Автор: Анна
Источник: Neurohive